


Les systèmes d’intelligence artificielle sont souvent perçus comme meilleurs que l’humain aux tâches qu’ils réalisent, alors qu’en réalité leurs performances sont parfois très surestimées.
L’IA est confrontée à de nombreux défis techniques dont celui de la robustesse au sein d’un environnement réel. La robustesse d’un système d’IA est sa capacité à garantir des performances satisfaisantes qui se maintiennent dans le domaine dans lequel il évolue.
L’importance d’un dataset de qualité : étiquetage des données et data augmentation
Les questions de robustesse du machine learning dépendent en premier lieu de la qualité du data set fourni au système d’IA pour son entraînement. Les data scientists doivent s’assurer, tout d’abord, de manipuler une base d’entraînement propre, c’est-à-dire sans la présence de biais potentiels, de données corrompues ou mal étiquetées venant fausser les résultats du système. Dans cet article nous nous concentrerons particulièrement sur l’étiquetage des données. Ces dernières sont l’épine dorsale des algorithmes d’IA fondés sur le machine learning, mais sont aussi leur principale cause d’échec lorsqu’elles ne sont pas de bonne qualité ou qu’elles ne sont pas adaptées au besoin spécifique du système d’IA.
Le volume de données disponible est devenu exponentiel car les machines se sont elles aussi mises à produire de la donnée en continu. Néanmoins, le challenge de la qualité de leur étiquetage persiste. Selon une étude du MIT, les dix ensembles de données d’IA les plus cités sont truffés d’erreurs d’étiquetage, avec notamment des images de champignons étiquetées comme étant une cuillère ou encore une note aiguë d’Ariana Grande issue d’un fichier audio étiquetée comme étant « sifflet »1. Ces erreurs d’étiquetage viennent alors fausser les performances du système d’IA. L’adage classique en informatique ici s’applique: “garbage in, garbage out”, si la qualité est mauvaise, le système le sera aussi.
Deuxièmement, les data scientists doivent veiller à ce que leur base d’entraînement soit suffisante. En effet, un dataset dit insuffisant selon les 4V du Big Data (volume, vélocité, variété et la valeur) nécessite la mise en place d’une augmentation des données, et ce peu importe leur type (image, fichier audio etc)2. Une augmentation de données permet de renforcer la robustesse d’un système d’IA au sein d’un domaine qui est déjà en partie couvert par ce dernier3.
Cependant, il ne s’agit pas d’une solution miracle, puisqu’une base d’entraînement trop restreinte ne permettra pas forcément au système de performer sur un domaine non couvert malgré l’utilisation d’une augmentation de données. L’augmentation des données permet de générer de nouvelles données à partir d’une donnée connue en les perturbant plus ou moins fortement. Il s’agit par l’exemple de l’ajout d’un flou d’un degré d’intensité variable sur une image, ou d’appliquer des rotations sur celles-ci. L’augmentation des données permet de renforcer la robustesse d’un système d’IA en l’entrainant sur des données déclinées en plusieurs variations afin d’aider le système à être résistant aux perturbations considérées.
La robustesse adversariale
Mais l’étiquetage et la qualité du dataset ne sont pas les deux seuls défis auxquels sont confrontés les data scientists lors de la conception de leur système d’IA. La robustesse adversariale est aujourd’hui un champ de recherche actif du fait de la multiplication des attaques adversariales.
La genèse de ce type d’attaque consiste à modifier des pixels de l’image (invisible à l’œil nu), afin de duper l’identification et la classification de l’image par l’IA. Ce type d’attaque s’apparente pour le système à une illusion d’optique dont le but est de lui faire prendre la mauvaise décision4. Ces attaques peuvent s’avérer particulièrement dangereuses dans plusieurs situations. Par exemple, un système d’IA embarqué à bord d’une voiture sans chauffeur peut être confronté à une attaque adversariale et mettre les passagers en danger. Cette dernière se concrétise par la présence d’autocollants sur l’un des panneaux à détecter, venant mettre à mal la capacité de distinguer un panneau des autres5. C’est ce qu’ont découvert des chercheurs de l’université du Michigan après avoir collé des autocollants sur un panneau Stop que le système d’IA a identifié comme étant un panneau affichant “45 mph”6.
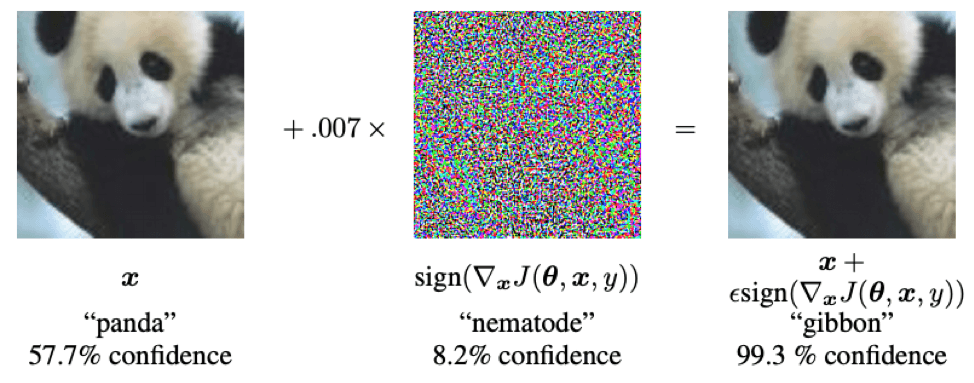
Les phases de conception et de validation sont fondamentales afin qu’un système d’IA atteigne et garantisse ses objectifs de performance. Durant ces étapes des outils tels que Saimple permettent par exemple d’accompagner les ingénieurs pour mesurer le risque adversarial causé par leur système et enrichir le processus qualité mis en œuvre. De plus, la standardisation de l’IA qui se développe permet de s’assurer des exigences de robustesse à ce genre d’attaque des systèmes d’intelligence artificielle. En témoigne d’ailleurs la parution de la norme ISO 24029-1 “Assessment of the robustness of neural networks”. Cette norme vise à renforcer le processus pour s’assurer de la fiabilité de la conception et de la validation des systèmes d’intelligence artificielle.
L’impact du domaine d’emploi sur la robustesse d’un système d’IA
La robustesse se vérifie par rapport à un domaine d’usage spécifique. Lorsque ce dernier est amené à évoluer ou à changer, il est probable que le système d’IA initial ne soit pas robuste sur ce nouveau domaine. En effet, il sera confronté à des situations inconnues jusqu’alors car non considérées par les datas scientists lors de la phase d’entraînement et de validation. Plus le nouveau domaine s’éloigne de celui prévu initialement, plus la robustesse a de chances de baisser, car sa capacité à généraliser sera mise à rude épreuve.
Prenons l’exemple d’un système d’IA dont le rôle est de faire de la reconnaissance faciale. Il y a fort à parier que ce même système soit incapable d’obtenir des performances similaires lorsqu’il est placé sous l’eau puisqu’il n’a pas été entraîné pour ce domaine d’emploi. En effet, les caméras de ce système seront incapables de détecter des visages sous l’eau, puisque les images récoltées seront distordues à cause de l’eau ou du port d’un masque et d’un tuba par exemple. Les données contenues dans la base d’entraînement et celles récoltées en situation réelle seront fondamentalement différentes, par conséquent le système sera faillible.
Mais la robustesse peut aussi varier au sein du domaine d’emploi. En effet, un domaine d’emploi peut être difficile à encadrer de par le nombre de paramètres à prendre en compte le caractérisant. Prenons l’exemple du domaine d’emploi au sein duquel évoluent les voitures sans chauffeur. Il serait difficile, voire impossible, de définir l’ensemble des règles et des contextes qui définissent ce qu’est “conduire sur une route en France”.
Le moindre oubli d’un paramètre (climatique, routier, environnemental…), au sein du domaine d’emploi, peut venir mettre en défaut les performances d’un système d’IA.
Par exemple, au sein d’un système embarqué à bord d’une voiture sans chauffeur, de nombreux paramètres tels que l’endommagement des panneaux (rouille, saleté etc) peuvent mettre en échec le système d’IA chargé de les reconnaitre. Cela, alors même que l’environnement dans lequel évolue le système est bien prédéfini.
Ainsi la preuve de la robustesse des systèmes reste encore aujourd’hui l’un des principaux objectifs pour favoriser l’adoption des IA. Pour s’assurer que les performances soient à la hauteur des attentes malgré de nombreux défis (étiquetage des données, attaques adversariales, définition du domaine d’emploi,), les ingénieurs peuvent s’appuyer, en plus des méthodes statistiques usuelles, sur des preuves formelles.
- Error-riddled data sets are warping our sense of how good AI really is ↩︎
- Les « 4V » | Thales Group ↩︎
- The Four V’s of Big Data ↩︎
- Que sont les adversarial examples ? – United Brands Association ↩︎
- Machine Learning et sécurité: les exemples contradictoires | by Julien Corb | Medium ↩︎
- Un simple autocollant pour tromper l’intelligence artificielle de la voiture autonome ↩︎





