Depuis des années, l'électrocardiogramme (ECG) s'est imposé comme la référence pour la détection de cette pathologie, captant avec précision les activités électriques du cœur. Les avancées technologiques ont constamment affiné la qualité et la précision des appareils, qu'ils soient analogiques, numériques, stationnaires ou portatifs.
Avec l'émergence de l'intelligence artificielle, une nouvelle opportunité se dessine pour renforcer la précision des diagnostics. En effet, en intégrant l'IA, il est possible d’améliorer la détection des arythmies cardiaques de ces appareils.
Néanmoins, dans le contexte médical, la confiance dans les dispositifs est primordiale, les solutions basées sur l'IA se doivent d’être non seulement fiables, mais également transparentes, explicables et compréhensibles.
C'est dans ce cadre que ce cas d'utilisation introduit Saimple. L’objectif est d'exploiter les fonctionnalités de l’outil pour apporter des éléments d’explicabilité et valider la robustesse de modèles d'IA spécialisés dans l'analyse d'ECG pour la détection d'arythmies.
L'utilisation de Saimple permet d’identifier les motifs cardiaques essentiels que le modèle d'IA utilise pour son diagnostic, tout en évaluant sa capacité à rester stable face à des variations d'entrées.
La robustesse et l'explicabilité, dans ce contexte, ne sont pas de simples avantages ; elles sont des impératifs pour garantir la sécurité des patients, établir la confiance auprès des professionnels de la santé, et répondre de manière satisfaisante aux normes établies par l'EU AI-Act pour les systèmes d'IA à haut risque.
Le jeu de données est obtenu à l'aide de l'enregistrement d'un électrocardiogramme noté ECG. Pour un patient ayant un rythme cardiaque normal, l'ECG met en évidence cinq ondes :

Figure 1: Schéma d'un rythme cardiaque normal
Onde P : L'onde P représente la dépolarisation auriculaire, c'est-à-dire l'activation des oreillettes du cœur. Lorsque le nœud sino-auriculaire (SA) génère un signal électrique, les oreillettes se contractent pour propulser le sang vers les ventricules. L'onde P correspond à cette activation électrique des oreillettes, indiquant leur contraction.
Complexe QRS : Le complexe QRS est composé de trois ondes distinctes : l'onde Q, l'onde R et l'onde S. Ces ondes représentent la dépolarisation ventriculaire, c'est-à-dire l'activation des ventricules du cœur.
Onde Q : L'onde Q est une petite onde négative qui peut être présente dans certaines dérivations de l'ECG. Elle indique le début de la dépolarisation ventriculaire, généralement dans le septum interventriculaire (la paroi qui sépare les ventricules gauche et droit).
Onde R : L'onde R est une onde positive qui suit généralement l'onde Q. Elle représente la dépolarisation ventriculaire continue, indiquant l'activation des ventricules dans leur ensemble.
Onde S : L'onde S est une onde négative qui suit l'onde R. Elle représente également la dépolarisation ventriculaire et peut varier en taille et en forme en fonction de l'ECG et de la dérivation considérée.
Onde T : L'onde T représente la repolarisation ventriculaire, c'est-à-dire la phase de récupération électrique des ventricules après leur contraction. Elle indique que les ventricules sont prêts à se contracter à nouveau lors du prochain cycle cardiaque. L'onde T est généralement une onde positive, mais elle peut également être négative dans certaines conditions.
Ces différentes ondes (P, QRS et T) sont essentielles pour l'interprétation de l'ECG et permettent d'évaluer l'activité électrique du cœur, en identifiant d'éventuelles anomalies ou dysfonctionnements cardiaques. (1)
Selon la convention, le terme "rythme sinusal normal" (RSN) ou "rythme sinusal régulier" (RSR) indique que non seulement les ondes P (qui reflètent l'activité du nœud sinusal) ont une morphologie normale, mais aussi que toutes les autres mesures de l'ECG sont également normales. Les critères comprennent donc les éléments suivants :
L'arythmie se produit lorsque des anomalies surviennent dans les ondes P et le complexe QRS, en particulier lorsque la synchronisation entre la contraction des oreillettes et celle des ventricules est altérée. Normalement, l'onde P est toujours positive, donc si ce n'est pas le cas, cela peut indiquer la présence d'une anomalie.
Pour ce cas d'utilisation, deux jeux de données disponibles sur Kaggle vont être utilisés :
Les deux jeux de données contiennent 188 colonnes dont la dernière indique l'appartenance aux cinq classes suivantes :
Classe 0 : Rythme non ectopique normal
Cette classe représente les rythmes cardiaques normaux et non perturbés. Les données associées à cette classe sont celles où le cœur bat régulièrement et sans anomalie.
Classe 1 : Rythme ectopique supraventriculaire
Les rythmes ectopiques supraventriculaires se produisent lorsque des impulsions électriques anormales se forment dans les parties supérieures du cœur, telles que les oreillettes. Cette classe comprend des rythmes cardiaques anormaux qui proviennent des ondes P ou un intervalle PR court ou un complexe QRS étroit ou une absence de complexe.
Classe 2 : Rythme ectopique ventriculaire

Un rythme de fusion se produit lorsqu'il y a une combinaison d'impulsions électriques normales et anormales qui se produisent simultanément dans le cœur. Cette classe représente des situations où le rythme cardiaque est une combinaison de battements normaux et anormaux.
Classe 4 : Rythme inconnu
La classe des rythmes inconnus regroupe les données qui ne peuvent pas être classifiées avec certitude dans l'une des autres catégories. Cela peut être dû à des erreurs de mesure, à des artefacts ou à des modèles de rythme cardiaque peu fréquents ou non identifiés.

Avant toute analyse, il est nécessaire d'effectuer un pré-traitement sur le jeu de données afin de permettre au modèle de mieux apprendre.
Dans les jeux de données de ce type, que ce soit pour prédire des défauts dans le cadre de la maintenance prédictive ou détecter des fraudes sur les cartes de crédit, les cas anormaux sont rarement observés. Cela entraîne un déséquilibre au niveau des classes dans le jeu de données. Il est donc nécessaire de trouver une méthode adaptée au cas d'utilisation pour rééquilibrer ces classes. Dans cette étude, les échantillons des classes sous-représentées sont rééchantillonnés afin d'atteindre la même taille d'échantillon que la classe sur-représentée.
Pour des séries temporelles, le rééquilibrage des classes nécessite une approche légèrement différente par rapport aux données tabulaires classiques. Lorsque l'on travaille avec des séries temporelles, il est essentiel de tenir compte de la dépendance temporelle des données pour éviter d'introduire un biais dans le modèle lors du rééquilibrage.
Il existe de nombreuses approches adaptées au rééquilibrage des classes dans des séries temporelles :
SMOTE-TS génère de nouvelles séries synthétiques en interpolant linéairement entre des séries temporelles similaires. Cela permet de maintenir la dépendance temporelle dans les nouvelles séries générées.
Tirage aléatoire avec remise consiste à augmenter le nombre d'échantillons de la classe minoritaire en tirant aléatoirement des échantillons de cette classe avec remise, c'est-à-dire en autorisant la duplication d'échantillons existants.
Dans ce cas d’utilisation, le tirage avec remise est privilégié. En effet, le tirage avec remise est une technique couramment utilisée pour effectuer le sur-échantillonnage dans les séries temporelles.
Il est important de noter que le tirage avec remise peut entraîner une augmentation significative de la taille de la classe minoritaire, ce qui peut éventuellement conduire à un sur-apprentissage (overfitting).
Nous avons utilisé comme base le document [5], qui présente une architecture composée d'une succession de couches de convolution 1D. Et nous avons adopté des techniques de transformation de série temporelle en image, ce qui nous a conduit à utiliser un modèle contenant des convolutions 2D.
Dans le cadre de notre étude comparative, nous avons conservé la même architecture pour les différents modèles. Seules les couches de convolution 1D ont été remplacées par des convolutions 2D et les opérations de MaxPooling1D ont été remplacées par des MaxPooling2D. Cette approche nous permet de comparer les performances des différents modèles tout en gardant une base commune pour les évaluations.
Le modèle contient quatre blocs où un bloc comporte les couches suivantes :
Ensuite, le modèle contient trois couches denses et la dernière couche est la fonction d'activation Softmax qui est utilisée pour renvoyer un score d’appartenance pour chaque classe.
Ce modèle utilise une approche à base de convolution 1D pour extraire des caractéristiques importantes des signaux de rythme cardiaque. Les couches de MaxPool1D et Flatten sont ensuite utilisées pour réduire la dimension des données et les préparer pour les couches denses qui effectueront la classification finale des rythmes cardiaques. Cette architecture est couramment utilisée dans les tâches de traitement du signal, car elle permet de capturer efficacement les motifs importants dans des données temporelles.
Le deuxième modèle utilise une architecture similaire à celle du modèle précédent, mais avec une différence clé : il est conçu pour traiter des données d'entrée sous forme d'images. Pour cette raison, les couches de convolution 1D du modèle précédent sont remplacées par des couches de convolution 2D dans ce modèle, et les couches de MaxPool1D sont remplacées par des couches de MaxPool2D.
La modification de la dimensionnalité des couches convolutives et de pooling est une adaptation nécessaire pour traiter des données d'entrée présentées sous forme d'images, qui sont des structures bidimensionnelles (matrices de pixels) plutôt que des séquences unidimensionnelles comme les données de rythme cardiaque dans le modèle précédent.
Le modèle contient quatre blocs où un bloc comporte les couches suivantes:
Ensuite, le modèle contient trois couches denses et la dernière couche est la fonction d'activation Softmax qui est utilisée pour renvoyer un score d’appartenance pour chaque classe.
Afin de pouvoir utiliser des modèles de type convolution en 2D, il faut transformer la série temporelle en 2D. Pour cela il est possible d’utiliser une méthode appelée Gramian Angular Field.
Gramian Angular Field (GAF) est une transformation qui permet de représenter une série temporelle sous forme d'une image. Elle capture les relations angulaires entre les points de la série temporelle. L’image résultante du GAF peut être ensuite utilisée comme entrée pour des modèles basés sur les réseaux de neurones convolutifs 2D. Les avantages de cette méthode sont :

Figure 2: Exemple de transformation de série temporelle en image à l'aide de la méthode GAF
Afin de comparer conv 1D et conv 2D nous allons étudier leurs matrices de confusion. La matrice de confusion pour le modèle conv1D révèle que les classes 0, 2 et 4 ont un score de prédiction d'au moins 97%, ce qui indique une bonne précision (appelée « accuracy »). Les classes 1 et 3 ont un score de prédiction d'au moins 78% pour le modèle conv1D, mais inférieur à 80%, ce qui reste acceptable. Cependant, il est important de se demander pourquoi la classe 1 est prédite comme la classe 0 à hauteur de 15%. De même, la classe 3 est prédite comme la classe 0 à hauteur de 11%. Saimple permet d’aider à comprendre ces erreurs de prédiction et pourquoi le réseau confond un rythme cardiaque normal avec des rythmes ectopiques supraventriculaires et des rythmes de fusion. Il permet une meilleure compréhension des raisons pour lesquelles ces confusions se produisent et aide à identifier les motifs spécifiques qui influencent ces prédictions erronées.
La matrice de confusion pour le modèle conv 2D révèle que globalement le modèle obtient une accuracy d’au moins 88 % ce qui est mieux que le modèle conv1D.
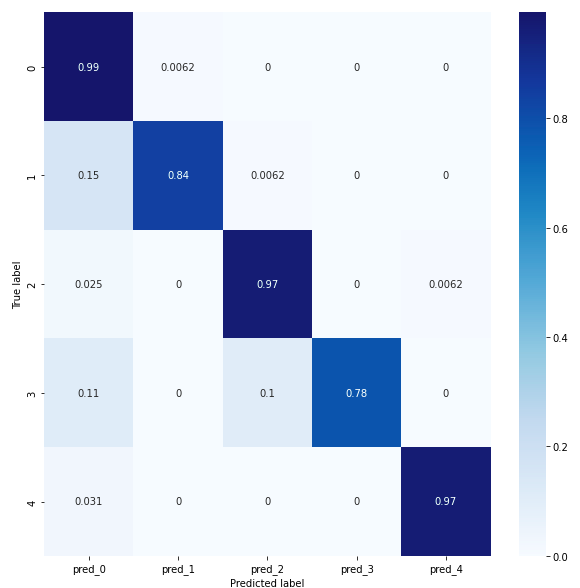
Matrice de confusion conv1D.
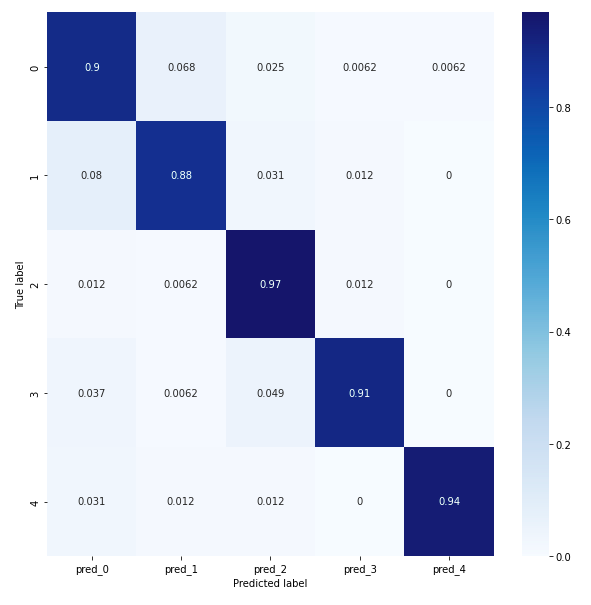
Matrice de confusion conv2D.
Lors de la détection de l'arythmie cardiaque, le choix entre un modèle de convolution 2D (Conv2D) et un modèle de convolution 1D (Conv1D) dépend des caractéristiques spécifiques des données et de la manière dont on souhaite les représenter. Bien que les modèles convolutifs 1D soient spécifiquement conçus pour traiter les données séquentielles, les modèles convolutifs 2D peuvent également exploiter les relations spatiales et temporelles. Ils peuvent capturer des motifs qui se répètent à la fois dans l'axe temporel et l'axe spatial, ce qui peut être utile pour les séries temporelles avec des motifs périodiques ou récurrents. Dans le cas de l'arythmie cardiaque, cela peut être bénéfique pour détecter des motifs complexes dans l'ECG qui indiquent des anomalies cardiaques spécifiques.
Cependant, il est important de noter que l'utilisation d'un modèle Conv2D peut également présenter des inconvénients. L'un des inconvénients potentiels est que les modèles Conv2D peuvent nécessiter plus de données et avoir des exigences de calcul plus élevées que les modèles Conv1D, en raison du nombre de paramètres supplémentaires nécessaires pour traiter les données 2D.
Or, un modèle Conv1D peut être suffisant pour détecter l'arythmie cardiaque et peut donc permettre de limiter les ressources nécessaires à l’exploitation des résultats. Les entrées étant composées d'un seul signal ECG, les modèles Conv1D peuvent certainement capturer les variations temporelles des signaux 1D de manière suffisamment efficace.
Afin d’évaluer la performance des deux modèles, une étude peut être mené pour mesurer la stabilité de prédiction des modèles. Pour cela l’interprétation abstraite permet de modéliser un ensemble de variation possible d’une série temporelle en un seul objet, appelé enveloppe abstraite. Cela offre l'avantage de regrouper toutes les séries temporelles et d’évaluer le comportement du modèle sur l’ensemble en une seule analyse. Cette enveloppe représente l’ensemble de toutes les perturbations potentielles d'un rythme cardiaque contenu entre deux séries temporelles extrêmes. En rassemblant ces informations essentielles au sein d'une enveloppe unique, il devient possible d'appréhender globalement les variations de comportement du modèle sur des versions même très irrégulières de rythme cardiaque, facilitant ainsi l'analyse et la détection d'anomalies éventuelles. Cette approche simplifiée permet de gagner en efficacité tout en fournissant une vue d'ensemble complète pour une prise de décision éclairée en matière de santé cardiaque.

La série temporelle transformée en image à l’aide de méthode GAF à l’aide d’une visualisation 3D

L'évaluation des performances des deux modèles, conv1D et conv2D, a été réalisée en utilisant l'intégralité du jeu de données de test, composé de 810 rythmes cardiaques, afin de déterminer leur capacité à prédire avec précision. Pour cette comparaison, trois volumes d'enveloppe abstraite (qui correspondent au volume maximal de bruit considéré) ont été sélectionnées : 1e-6, 1e-5 et 1e-4.
Initialement, d'après les résultats de la matrice de confusion, le modèle conv2D semblait légèrement supérieur en termes de performances. Cependant, une question cruciale subsiste : est-ce que, face à différents niveaux de bruit appliqués au modèle, les deux modèles maintiendraient leur niveau de précision ? Cette interrogation essentielle suscite l'intérêt de vérifier comment chaque modèle se comporte avec différentes épaisseurs d'enveloppe et d'évaluer leur robustesse face aux perturbations du signal. Une analyse approfondie de ces aspects permet de fournir des informations utiles pour choisir le modèle le plus adapté aux exigences spécifiques de l'application en question.
À l’aide de Saimple, il est possible d’analyser les valeurs de dominance de l'évaluation des prédictions d'un modèle, trois termes sont utilisés : "Dominant", "Dominated" et "Conflict".
1. "Dominant" fait référence à une évaluation où la classe prédite pour l’ensemble des séries temporelles considérées par le modèle correspond exactement à la classe véritable. Cela signifie que le modèle a correctement identifié la catégorie à laquelle appartient l’ensemble des entrées considérées.
2. "Dominated" décrit une évaluation où la classe prédite par le modèle ne correspond pas à la classe véritable. En d'autres termes, le modèle a commis une erreur en prédisant la mauvaise catégorie pour l’ensemble des entrées considérées.
3. "Conflict" désigne une évaluation où les scores des classes prédites par le modèle ont des valeurs équivalentes. Dans cette situation, le modèle peut être incertain quant à la classe appropriée pour l’ensemble des entrées, car plusieurs classes ont des scores similaires.
Ces termes aident à évaluer la performance d'un modèle et à comprendre comment il gère les prédictions pour différentes classes d’entrées. L'analyse de ces résultats peut être utile pour améliorer le modèle en identifiant les domaines où il est le plus performant et les aspects où il pourrait nécessiter des ajustements pour l’améliorer.
Le graphique ci-dessous offre une vue d'ensemble de la fréquence d'apparition des termes "Dominant", "Dominated" et "Conflict" pour la vraie classe, pour les deux modèles conv1D et conv2D.

Une observation importante réside dans le fait que, pour le modèle conv1D, le nombre de rythmes cardiaques correctement classés reste constant. En revanche, pour le modèle conv2D, ce nombre diminue, ce qui suggère que ce modèle éprouve des difficultés à classifier certains rythmes cardiaques. Surtout que le nombre de cas conflictuels augmente également. Il semble que les données d'entrées soient plus sensibles au bruit dans le cas du modèle conv2D, entraînant une précision de classification plus faible pour certains rythmes cardiaques. Ces premiers résultats indiquent que le modèle conv1D présente une stabilité supérieure par rapport au modèle conv2D, du moins dans les conditions d'évaluation actuelles. Cependant, pour parvenir à des conclusions plus définitives, il serait judicieux d'approfondir l'analyse en examinant davantage de paramètres et de scénarios d'évaluation.
Dans la deuxième expérimentation, un volume de bruit de 1e-5 a été utilisé.

Comme prévu, le modèle conv2D montre une forte diminution du nombre de rythmes cardiaques correctement classés. En revanche, le modèle conv1D maintient un nombre constant de rythmes cardiaques correctement classés malgré ce niveau de bruit. Ces résultats confirment que le modèle conv1D semble être plus stable et résilient face au bruit ajouté aux données que le modèle conv2D.
Cependant, la question clé demeure : jusqu'à quel niveau de bruit le modèle conv1D reste stable ? Pour répondre à cette question, il serait pertinent de poursuivre l'expérimentation en augmentant progressivement le volume de bruit et en surveillant comment le modèle conv1D réagit. Cela permettra de déterminer le seuil à partir duquel la précision du modèle conv1D commence à diminuer, fournissant ainsi des informations cruciales pour évaluer les limites de performance de ce modèle dans des conditions de données bruitées. En résumé, malgré les bonnes caractéristiques du modèle conv1D, il est essentiel d'explorer plus en profondeur ses performances en fonction du volume de bruit pour obtenir une évaluation plus précise de sa robustesse.
Dans cette troisième expérimentation, un niveau de bruit de 1e-4 a été appliqué aux données.

Les résultats montrent que le modèle conv2D n'est plus capable de classer correctement les rythmes cardiaques à ce niveau de bruit, montrant ainsi une dégradation significative de sa performance.
En revanche, le modèle conv1D présente des résultats intéressants. Pour les rythmes cardiaques de classe 0 (rythme normal), la proportion de cas correctement classés semble rester constante malgré le bruit. Cependant, une observation intrigante est faite pour les rythmes cardiaques mal classés au départ : le modèle semble ne plus être en mesure de les classer correctement. Quant aux rythmes cardiaques de classe 1, la proportion de correctement classés a fortement diminué, passant de 78% à 20%. Cette baisse significative de performance soulève des questions sur les raisons de ce phénomène.
Pour les trois autres classes, on observe une légère baisse du nombre de rythmes cardiaques bien classés, ce qui indique que le modèle conv1D commence également à montrer des signes de sensibilité au bruit à ce niveau.
Ces résultats soulignent l'importance de comprendre comment le modèle conv1D réagit face à des niveaux de bruit plus élevés et mettent en évidence la nécessité de déterminer le seuil limite à partir duquel sa performance commence à se dégrader de manière significative. Une analyse plus approfondie de ces résultats pourrait fournir des informations pour évaluer la robustesse du modèle conv1D dans des conditions de données bruitées et identifier les limites de sa performance.

Il est possible d’envisager l’ajout de bruit de manière ciblée à certaines parties du rythme cardiaque pour évaluer la robustesse d’un système face à des variations spécifiques liées à des contextes métiers particuliers. Cette approche permettrait de simuler des conditions réalistes et de tester la capacité d’un système à maintenir sa performance malgré des perturbations spécifiques à un domaine d’application donné.
Dans cette étude, nous focaliserons notre analyse sur les cas où un rythme cardiaque normal est incorrectement classé comme étant un rythme anormal et les résultats du modèle conv1D. Pour ce faire, nous utiliserons l'outil Saimple pour identifier les rythmes qui ont rencontré des difficultés de classification, caractérisés par les termes "dominated" et "conflict", en fonction d'un niveau de bruit spécifique. L'objectif est de comprendre les raisons sous-jacentes à ces erreurs de prédiction et de déterminer si le modèle présente des vulnérabilités selon les volumes de bruits. En analysant ces cas de classification erronée, nous pourrons identifier les motifs distinctifs qui ont influencé les mauvaises prédictions et évaluer la capacité du modèle à distinguer les rythmes cardiaques normaux des rythmes anormaux dans des conditions bruitées. Cette analyse approfondie permettra d'obtenir des informations essentielles pour améliorer la précision et la fiabilité du modèle de détection d'arythmies cardiaques. Nous allons d’ailleurs pouvoir trouver des erreurs d’annotation grâce à cette approche.
Pour ces volumes de bruits, un seul rythme est mal classé (dominated) et aucun n'est en conflit.

Figure 5: Rythme cardiaque, appartenant à la classe 0, mal classé
En analysant visuellement ce rythme cardiaque classé comme normal, il devient évident que sa reconnaissance en tant que rythme cardiaque normal est erronée. En effet, la présence du complexe QRS, qui est essentiel pour identifier un rythme cardiaque normal, est difficile à repérer dans cette séquence. Cette observation soulève des doutes quant à la qualité de l'annotation des données dans le jeu de données. Il est possible que certaines données aient été mal annotées, ce qui entraînerait des erreurs dans les prédictions du modèle d'intelligence artificielle. Une évaluation plus approfondie des annotations et une analyse plus rigoureuse des données pourraient permettre de résoudre ce problème et d'améliorer la précision de la détection des rythmes cardiaques anormaux. Il est crucial d'effectuer une vérification minutieuse de l'ensemble du jeu de données pour s'assurer de la qualité et de la fiabilité des annotations, garantissant ainsi des résultats plus fiables et précis dans le cadre de la détection des arythmies cardiaques.
Pour ce niveau de bruit spécifique, on observe que 18 rythmes cardiaques sont classés en "conflict", ce qui signifie que le modèle d'intelligence artificielle éprouve des difficultés à déterminer avec certitude la classe appropriée pour ces rythmes. Cette situation se produit lorsque les scores de prédiction des différentes classes sont similaires, ce qui rend le modèle incertain quant à la classe à laquelle appartient chaque rythme cardiaque. Ces résultats soulèvent des questions sur la capacité du modèle à traiter les données dans des conditions de bruit élevé et mettent en évidence la nécessité d'améliorer sa robustesse pour mieux gérer ces situations complexes. Une analyse plus approfondie de ces rythmes cardiaques en conflit pourrait fournir des informations importantes pour identifier les défis spécifiques que pose le bruit dans la détection des arythmies cardiaques et permettre d'affiner le modèle pour des performances plus fiables et précises.

Figure 6: Rythmes cardiaques, appartenant à la classe 0, mal classé

Figure 7: Rythmes cardiaques, appartenant à la classe 0, en conflit
Les observations effectuées sur les rythmes cardiaques mal classés remettent en question la qualité de l'annotation du jeu de données. En effet, on remarque que certains rythmes cardiaques sont mal annotés, car ils ne correspondent pas à des rythmes cardiaques normaux. Plus précisément, ces rythmes présentent des anomalies telles qu'un manque du complexe QRS ou une absence de visibilité des ondes P ou T. Cette situation indique clairement un problème dans l'annotation du jeu de données, ce qui peut grandement affecter la pertinence des résultats obtenus. La qualité des annotations dans les données est un aspect essentiel pour l’entrainement d'un modèle. Des données mal annotées peuvent avoir un impact significatif sur les performances du modèle, car il apprendra à partir de ces annotations incorrectes et peut conduire à des prédictions erronées.
L'augmentation du niveau de bruit nous a permis de mettre en évidence un grand nombre de rythmes cardiaques mal annotés, ce qui explique la perte de rythmes cardiaques bien classés pour l'ensemble des classes. Il sera alors possible de supprimer ou corriger les données mal annotées identifiées dans le jeu pour améliorer les performances du modèle. Saimple s'est révélé utile pour détecter des problèmes d'annotation dans le jeu de données. En identifiant les rythmes en conflit et dominés, Saimple nous a permis de constater des fragilités dans la stabilité des deux modèles, en particulier pour le modèle conv2D qui a montré une perte de performances dès un niveau de bruit de 1e-6, qui est relativement faible.
En conclusion, bien que les deux modèles aient montré de bonnes performances globales pour l'ensemble des classes au niveau de la matrice de confusion, ils n'ont pas été en mesure de déceler les erreurs d'annotation dans le jeu de données. Saimple s'est avéré être un outil précieux pour identifier ces erreurs en s’appuyant sur la sensibilité des modèles à des volumes de bruit variables. Cela permet d’adresser d’une nouvelle manière semi-automatisée l'importance de disposer de jeux de données correctement annotés pour obtenir de bonnes performances des modèles. De plus, l'analyse avec Saimple a mis en lumière des points de fragilité des modèles, ce qui permet d'orienter les futures améliorations et ajustements. Il sera par exemple possible d’enlever les données mal annotées pour obtenir une meilleure robustesse des modèles de détection d'arythmie cardiaque.
L'utilisation de l'intelligence artificielle, en particulier des techniques d'apprentissage automatique telles que les modèles de convolution 1D et 2D, offre une opportunité prometteuse pour améliorer la détection précoce des arythmies cardiaques.
L'arythmie est un trouble courant du rythme cardiaque qui peut entraîner des complications graves si elle n'est pas détectée et traitée rapidement. L'IA peut jouer un rôle crucial dans cette détection en analysant les signaux électrocardiographiques et en identifiant automatiquement les anomalies dans le rythme cardiaque.
Aussi, l’IA et les algorithmes de détection d’arythmie sont de plus en plus présents dans les applications de santé des montres connectées, permettant un suivi régulier de l’état de santé d’un grand nombre de personnes.
Aux vues des enjeux, il est donc nécessaire de s’assurer de la robustesse et de l’explication des algorithmes de détection d’arythmie.
Cette étude a permis de mettre en évidence l’importance de disposer d’un jeu de données correctement annoté dans le domaine de la détection de l’arythmie cardiaque. Les observations faites sur les rythmes cardiaques mal classés révèlent des erreurs d’annotation évidentes une fois les séries temporelles isolées pour analyse, avec certains rythmes cardiaques incorrectement étiquetés comme normaux alors qu'ils présentent des anomalies telles qu'un manque de complexe QRS ou l'absence d'ondes P ou T. Ces erreurs d'annotation ont un impact significatif sur la pertinence des résultats obtenus, compromettant la fiabilité de la détection de l'arythmie cardiaque.
L'expérimentation réalisée avec Saimple concernant l'augmentation du volume de bruit a permis de détecter un grand nombre de rythmes cardiaques mal annotés. En identifiant les rythmes en conflit et dominés, Saimple a permis de mettre en évidence les fragilités des deux modèles, en particulier pour le modèle conv2D, qui a montré une dégradation précoce de ses performances dès un niveau de bruit de 1e-6, soit un niveau relativement faible.
Ainsi, l’utilisation de Saimple a permis de détecter une fragilité dans les modèles et d’offrir des pistes d'amélioration et d'ajustement pour renforcer la robustesse des modèles de détection d'arythmie cardiaque. En continuant à explorer et à exploiter pleinement les capacités de Saimple, il est possible de perfectionner davantage les modèles et de fournir des outils plus performants pour la détection précoce et précise des arythmies cardiaques, contribuant ainsi à améliorer la prise en charge et le traitement des patients atteints de troubles cardiaques.
En somme, cette étude illustre comment l'intelligence artificielle peut être un outil précieux dans la détection des arythmies cardiaques, mais aussi l'importance de comprendre les performances et les limites de ces modèles pour une application clinique efficace et sûre.
Ecrit par Noëmie Rodriguez & Arnault Ioualalen & Baptiste Aelbrecht & Jacques Mojsilovic