What does data augmentation mean?
Data augmentation is used for improving deep learning robustness. For example, it can be applied on images for classification solutions. It is often necessary when confronted with a massive domain of use like an open world as it improves the robustness of a neural network. Data augmentation is useful but can be time-consuming thus slowing down your development. In order to scale down the cost of training, you need adequate data augmentation.
When performing your data augmentation Saimple can:
Data augmentation can be done using python within a framework such as pytorch, tensorflow or keras. And it can help your neural network have a better performance on a specific kind of perturbation. It can also help it to generalize more easily on new data. But there are many ways to choose the data augmentation useful for your network implementation, and they usually come also with their own settings that need to be customized. Facing a multidimensional problem, data augmentation can suddenly become a much more difficult problem to solve than anticipated. One wrong setup of a parameter of one data augmentation can have an impact on the outcome. And when training time is not fast enough, you might end up doing blindly your data augmentation on your deep learning model in order to still manage to meet your deadline.
Saimple can help you dramatically decrease the efforts needed to tailor your data augmentation. First by observing the features learned by the neural network you can detect what is already learned and what needs to be added through data augmentation. Then you can see the overall impact on the robustness of your neural network of each data augmentation. Selecting its correct parameters independently will stabilize quickly the setting of your data augmentation process.
Each data augmentation can have a different impact in terms of the overall robustness it will bring to a neural network. Some data augmentations will improve the stability of decisions of your neural network, others can have a detrimental effect. For now, the only way to measure the adequacy of the data augmentation is to calculate again and again the accuracy/recall analysis and observe if there is an improvement on a testing dataset. However, in the case of images, testing the image augmentation output on a testing set is not enough to build a strong proof of the robustness of the neural network.
With Saimple you can observe how much your newly trained neural network has improved in terms of stability. The more your neural network can handle noise the more efficient your data augmentation has been. In the following figure, several variations of data augmentation are done to the neural network. The more the curve is shifted to the right the more the neural network can handle noise in its input. Data augmentation in that case has improved the overall robustness of the neural network.
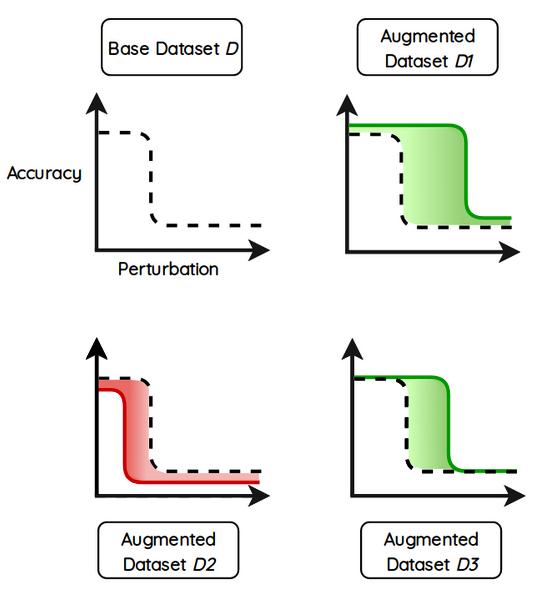
Fig 1 - Different data augmentation can lead to very different stability performance for the neural network. The more the neural network can handle noise in its dataset the better the data augmentation had a positive impact during the training phase.
Using data augmentation with python framework like keras, tensorflow or pytorch for instance, during the training phase will have an impact on the training duration. Indeed each new data you generate by data augmentation will have to be learned and might render the overall training more difficult. Adding more data points to be learned could create artificial clusters on which the neural network might be efficient but not very good at generalizing outside. Each time the process is not satisfactory, the whole learning process has to be done again from scratch. Therefore, having the right amount of data augmentation for the desired robustness can help you save a lot of time.
With Saimple you can easily measure the impact of your data augmentation for deep learning neural network models and thus control the amount of it you want in your training process. Once the settings of your data augmentation are set, you do not need to change then and you can still control over time that there is no regression in terms of stability.

