


Artificial intelligence systems are often perceived as being better than humans at the tasks they perform, when in fact their performance is sometimes greatly overestimated.
AI faces many technical challenges, including robustness in a real-world environment. The robustness of an AI system is its ability to guarantee satisfactory performance that is maintained in the domain in which it evolves.
The importance of a quality dataset: data labeling and data augmentation
The robustness of machine learning depends first and foremost on the quality of the data set provided to the AI system for training. Data scientists need to ensure, first of all, that they are handling a clean training set, i.e. one that is free from potential biases, corrupted or mislabelled data that could distort the results of the system. In this article we will focus particularly on data labeling. Data is the backbone of machine learning based AI algorithms, but it is also the main cause of failure when it is not of good quality or not adapted to the specific need of the AI system.
The volume of data available has become exponential as machines have also started to produce data continuously. Nevertheless, the challenge of the quality of their labelling persists. According to an MIT study, the ten most cited AI datasets are riddled with labelling errors, including images of mushrooms labelled as a spoon or a high-pitched note by Ariana Grande from an audio file labelled as a “whistle”1. These labelling errors then distort the performance of the AI system. The classic computer science adage applies here: “garbage in, garbage out”, if the quality is bad, the system will be too.
Secondly, data scientists must ensure that their training base is sufficient. Indeed, a dataset that is said to be insufficient according to the 4Vs of Big Data (volume, velocity, variety and value) requires the implementation of an increase in data, regardless of its type (image, audio file etc.)2. A data augmentation allows the robustness of an AI system to be enhanced within a domain that is already partially covered by the system3.
However, it is not a miracle solution, since a training base that is too small will not necessarily allow the system to perform in an uncovered domain despite the use of data augmentation. Data augmentation makes it possible to generate new data from known data by perturbing it to a greater or lesser extent. For example, this involves adding a blur of varying intensity to an image, or applying rotations to it. Data augmentation allows the robustness of an AI system to be strengthened by training it on data with several variations in order to help the system to be resistant to the perturbations considered.
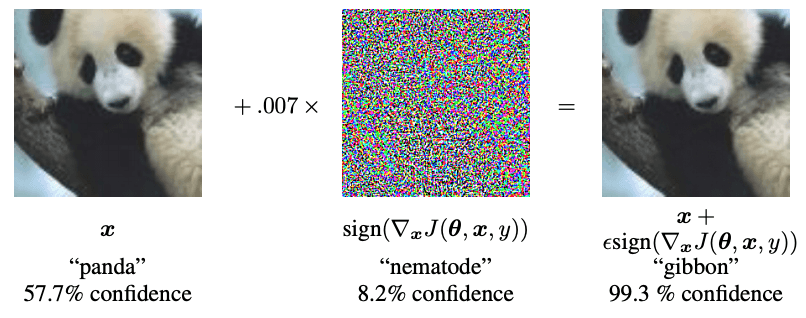
Adversarial robustness
But labeling and dataset quality are not the only two challenges facing data scientists when designing their AI system. Adversarial robustness is today an active field of research due to the multiplication of adversarial attacks.
The genesis of this type of attack consists in modifying pixels of the image (invisible to the naked eye), in order to fool the identification and classification of the image by the AI. This type of attack is similar to an optical illusion for the system, the aim of which is to make it make the wrong decision4. These attacks can be particularly dangerous in several situations. For example, an AI system in a driverless car may be confronted with an adversarial attack and put passengers at risk. The latter takes the form of stickers on one of the signs to be detected, undermining the ability to distinguish one sign from another5. Researchers at the University of Michigan found this to be the case after placing stickers on a Stop sign that the AI system identified as a “45 mph” sign6.
The design and validation phases are fundamental for an AI system to achieve and guarantee its performance goals. During these phases, tools such as Saimple can help engineers to measure the adversarial risk caused by their system and enrich the quality process implemented. Moreover, the standardization of AI which is developing makes it possible to ensure that artificial intelligence systems are robust to this type of attack. This is demonstrated by the publication of the ISO 24029-1 standard “Assessment of the robustness of neural networks”. This standard aims to strengthen the process for ensuring the reliability of the design and validation of artificial intelligence systems.
The impact of the domain of use on the robustness of an AI system
Robustness is verified in relation to a specific domain of use. When the latter is bound to evolve or change, it is likely that the initial AI system will not be robust to this new domain. Indeed, it will be confronted with situations that were previously unknown because they were not considered by the data scientists during the training and validation phase. The further the new domain is from the one initially planned, the more likely it is that robustness will be reduced, as its ability to generalize will be put to the test.
Take the example of an AI system whose role is to perform facial recognition. It is likely that this same system will be unable to achieve similar performance when placed underwater as it has not been trained for this area of use. Indeed, the cameras of this system will be unable to detect faces underwater, as the images collected will be distorted due to the water or the use of a mask and snorkel for example. The data contained in the training database and that collected in real life will be fundamentally different, so the system will be fallible.
But robustness can also vary within the domain of use. Indeed, a domain of use can be difficult to frame because of the number of parameters to be taken into account characterizing it. Let us take the example of the job domain in which driverless cars evolve. It would be difficult, if not impossible, to define all the rules and contexts that define “driving on a road in France”. The slightest omission of a parameter (climatic, road, environmental, etc.), within the field of use, can defeat the performance of an AI system.
For example, in an on-board system in a driverless car, many parameters such as damage to panels (rust, dirt, etc.) can defeat the AI system responsible for recognising them. This is despite the fact that the environment in which the system operates is well predefined.
Thus, proving the robustness of the systems is still one of the main objectives to promote the adoption of AI. To ensure that the performance is up to expectations despite many challenges (data labelling, adversarial attacks, definition of the domain of use,), engineers can rely, in addition to the usual statistical methods, on formal proofs.
- Error-riddled data sets are warping our sense of how good AI really is ↩︎
- Les « 4V » | Thales Group ↩︎
- The Four V’s of Big Data ↩︎
- Que sont les adversarial examples ? – United Brands Association ↩︎
- Machine Learning et sécurité: les exemples contradictoires | by Julien Corb | Medium ↩︎
- Un simple autocollant pour tromper l’intelligence artificielle de la voiture autonome ↩︎





